Apple在2017年发布了2个机器学习框架,Core ML和Vision,通过Core ML只需几行代码即可将强大的智能机器学习能力集成到开发者的应用程序中,Vision是一个计算机视觉任务框架,专注于处理包括图像和视频处理、人脸识别、文本识别和对象追踪等问题,Core ML提供了偏底层的机器学习能力,就像是Core Graphics,而Vision使用起来更像是UIKit的感觉,提供了更加简单的上层API供开发者调用。
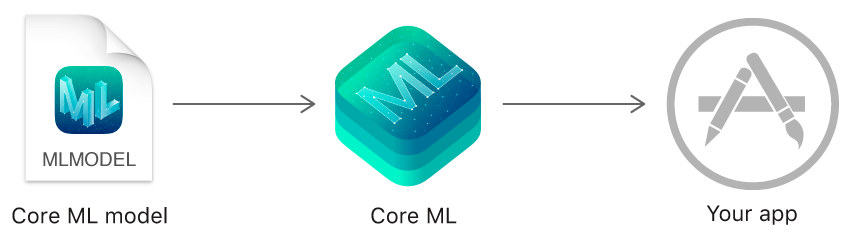
在Core ML问世一年后,Apple推出了自己的机器学习可视化训练工具:Create ML。Create ML十分强大,它使开发者能够以无需过多的机器学习知识为前提,快速轻松地创建用于各种任务的机器学习模型,这些模型通过Core ML可以直接集成到iOS或macOS应用中。Create ML采用UI交互方式来训练一个模型,几乎0代码成本,不懂开发的人也可以操作,训练完成会给出非常详细的训练结果,一键导出拖到自己的Xcode项目内就可以开始使用了,当然在App内的使用还是要有一定代码基础的。
还有很多方式可以将训练好的模型构建为CoreML模型,比如Turi Create,Swift for Tensorflow等,这里就不详细展开了。
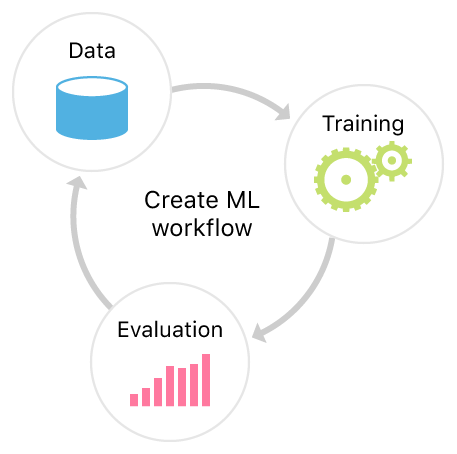
一般来说,创建一个机器学习(ML)的工作流程可以分为以下三个主要步骤。首先,我们需要收集和处理数据,因为这是机器学习模型的基础。其次,我们需要选择一个合适的模型,并对其进行训练。最后,我们需要评估模型的性能,并根据需要进行优化。这些步骤都是创建一个成功的机器学习工作流程所必需的。
数据集(Data Set)
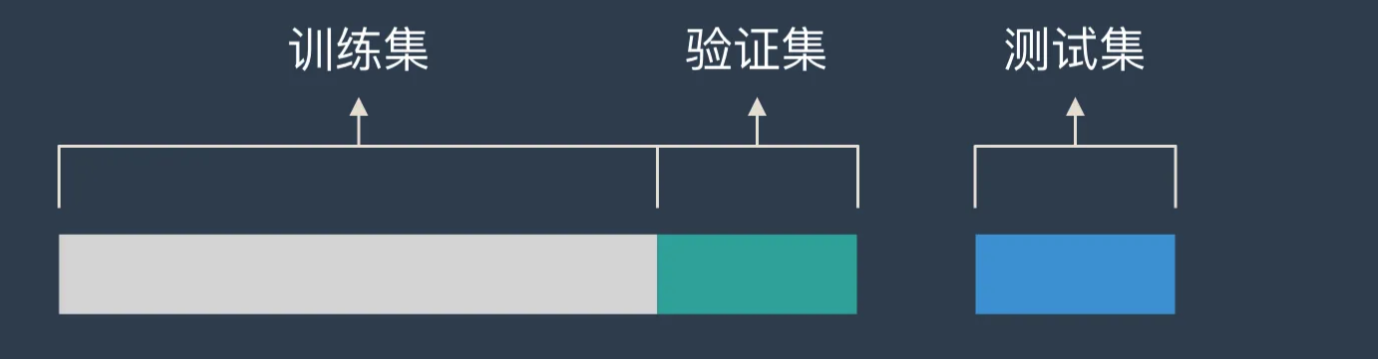
在机器学习或深度学习的过程中,我们通常需要三种不同的数据集来进行模型的训练和评估,这三种数据集分别是训练集,验证集和测试集。
- 训练集是用来训练机器学习模型的数据集。在训练集中,我们知道每个实例的输入和预期输出,然后我们将这些数据输入到模型中,让模型通过学习这些输入和输出的对应关系来进行学习。训练集的数据量通常占总数据量的大部分,因为模型的学习能力主要来自于训练集的数据。
- 验证集是在训练过程中用来调整模型参数和防止过拟合的数据集。在训练过程中,我们需要一部分数据来验证模型在未见过的数据上的表现,以此来调整模型的参数和结构,使模型不仅能在训练集上表现良好,同时也能在未见过的数据上有良好的表现。验证集的数据量通常小于训练集,但大于测试集。验证集在机器学习中起到了桥梁的作用,它既不参与模型的训练,也不参与模型的最终评估,它的角色是在训练和测试之间,用来优化和调整模型的。
- 测试集是用来在模型最终确定后,评估模型在未知数据上的性能,以确定模型的泛化能力。测试集的数据是模型在训练过程中从未见过的,通过测试集,我们可以了解到模型在面对未知数据时的表现能力,从而评估模型的泛化能力。测试集的数据量通常小于训练集和验证集,通过测试集,我们可以真实地了解到模型的性能和能力。
关于数据集各个部分的划分比例并没有明确的规定,不过可以参考以下3个原则:
- 对于小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。
- 对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
- 超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集。
数据集去哪儿找
获取数据集的方法有多种,可以从开放数据集平台如Kaggle, Google Dataset Search等获取,也可以通过自己收集构建。此外,一些公共机构或研究机构也会提供一些专业领域的数据集供研究者使用。我们这次要训练一个简单的图像分类模型,Kaggle上的Animals-10是一个不错的数据集,包含了10种常见动物的分类,一共28k张图片,这点儿图片在自己电脑上跑完全无压力。

预处理数据
在Create ML中,我们需要主动提供这训练集和测试集,Create ML可以根据我们上传的训练集自动抽取部分数据作为验证集。在下载完成原始数据集后,我们需要自己划分训练集和测试集,这里通过chatGPT来快速实现一个python脚本可以按指定比例将原始数据集划分为训练集和测试集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import os
import random
import shutil
import argparse
parser = argparse.ArgumentParser(description='Split training set into training and test sets.')
parser.add_argument('input_dir', type=str, help='Path to the input training set directory')
parser.add_argument('--test_ratio', type=float, default=0.2, help='Ratio of the test set (default: 0.2)')
args = parser.parse_args()
# 输入图片训练集目录和测试集比例
input_dir = args.input_dir
test_ratio = args.test_ratio
# 输出训练集和测试集目录
output_train_dir = os.path.join(os.path.dirname(input_dir), 'training_set')
output_test_dir = os.path.join(os.path.dirname(input_dir), 'test_set')
# 创建输出目录
os.makedirs(output_train_dir, exist_ok=True)
os.makedirs(output_test_dir, exist_ok=True)
# 遍历输入目录中的子目录
for subdir in os.listdir(input_dir):
subdir_path = os.path.join(input_dir, subdir)
if not os.path.isdir(subdir_path):
continue
# 获取子目录中的所有图片的路径
image_paths = []
for file in os.listdir(subdir_path):
if file.endswith('.jpg') or file.endswith('.png') or file.endswith('.jpeg'):
image_paths.append(os.path.join(subdir_path, file))
# 随机打乱图片路径
random.shuffle(image_paths)
# 划分训练集和测试集
split_index = int(len(image_paths) * (1 - test_ratio))
train_image_paths = image_paths[:split_index]
test_image_paths = image_paths[split_index:]
# 将训练集和测试集分别拷贝到输出目录
for image_path in train_image_paths:
dst_path = os.path.join(output_train_dir, subdir, os.path.basename(image_path))
os.makedirs(os.path.dirname(dst_path), exist_ok=True)
shutil.copyfile(image_path, dst_path)
for image_path in test_image_paths:
dst_path = os.path.join(output_test_dir, subdir, os.path.basename(image_path))
os.makedirs(os.path.dirname(dst_path), exist_ok=True)
shutil.copyfile(image_path, dst_path)
执行 python3 predata.py raw-img –test_ratio 0.2 命令会按8比2生成训练集和测试集,至此我们完成了数据的预处理,我们可以对执行几次命令产生不同的训练数据重复训练模型,直到满意为止。
使用 Create ML
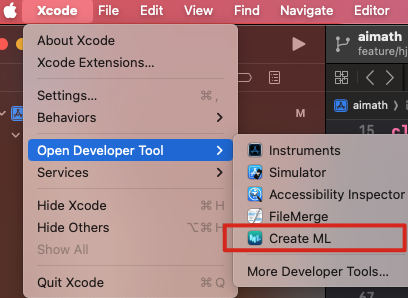
Create ML作为开发者工具被集成在Xcode当中,唤起路径如下。
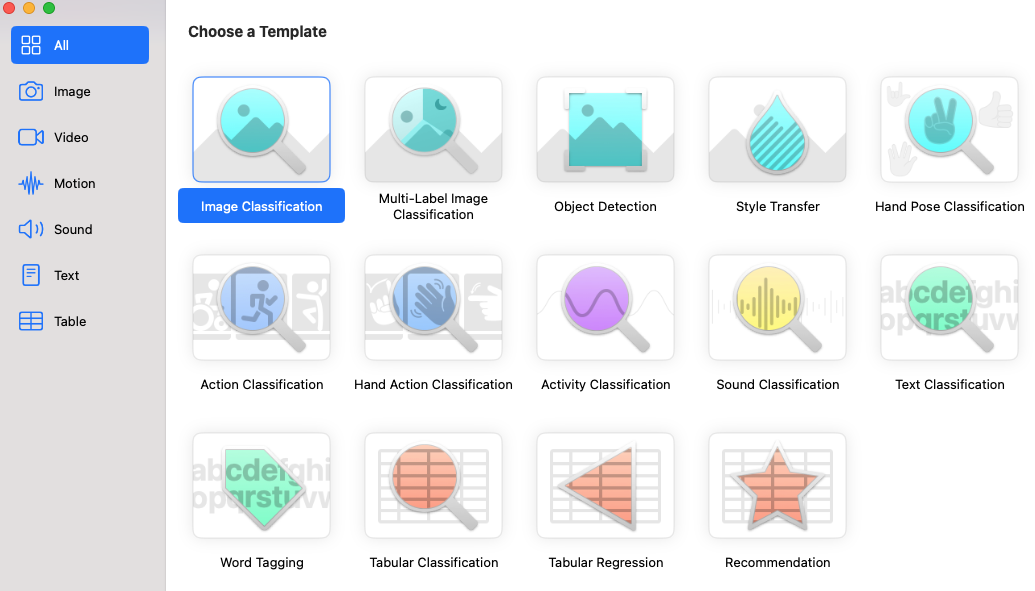
新建一个项目,Create ML默认提供了不同类型的机器学习任务,包括图像、文字、视频、音频等多种模板,这里我们选择图像分类。
图像分类
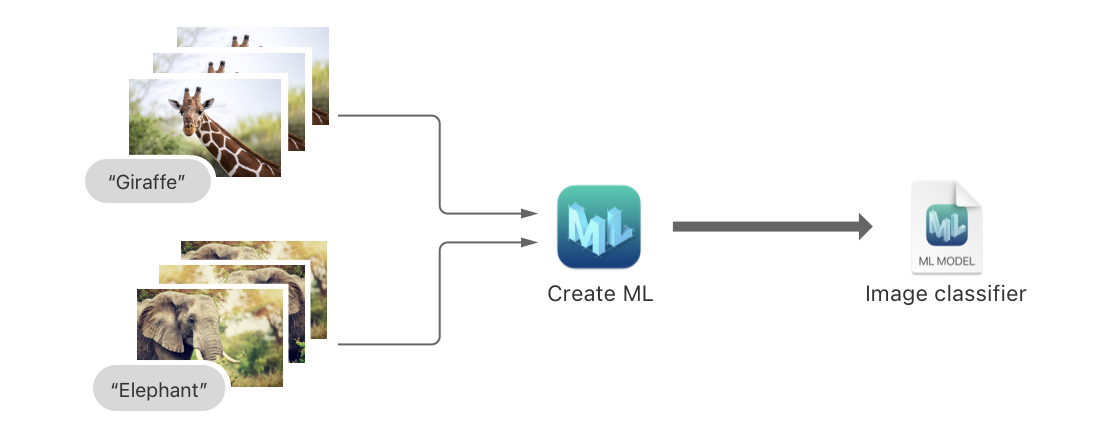
图像分类是机器学习的一个重要应用,它的目标是将输入的图像分配到预定义的类别之一。在我们的例子中,我们将使用十种动物的图像来训练模型,让模型学习如何区分这十种动物。这样,当我们将新的动物图像输入到模型中时,模型就可以预测出这是哪种动物。
Embedding
在机器学习中,特征抽取是一项关键的任务。特征抽取是将原始数据转换为机器学习算法可以理解的格式的过程。对于图像数据,特征可能包括颜色、形状、纹理等。这些特征被用来训练机器学习模型,使模型能够从图像中识别出有用的模式。以往想要让计算机表示一张图片可以使用像素表示法,如果每个像素均由RGB三个色值表示的话,一张图就需要 n x n x 3 个像素来表示,如果按照像素计算的方式去理解一张图,这个计算复杂度将是巨大的。
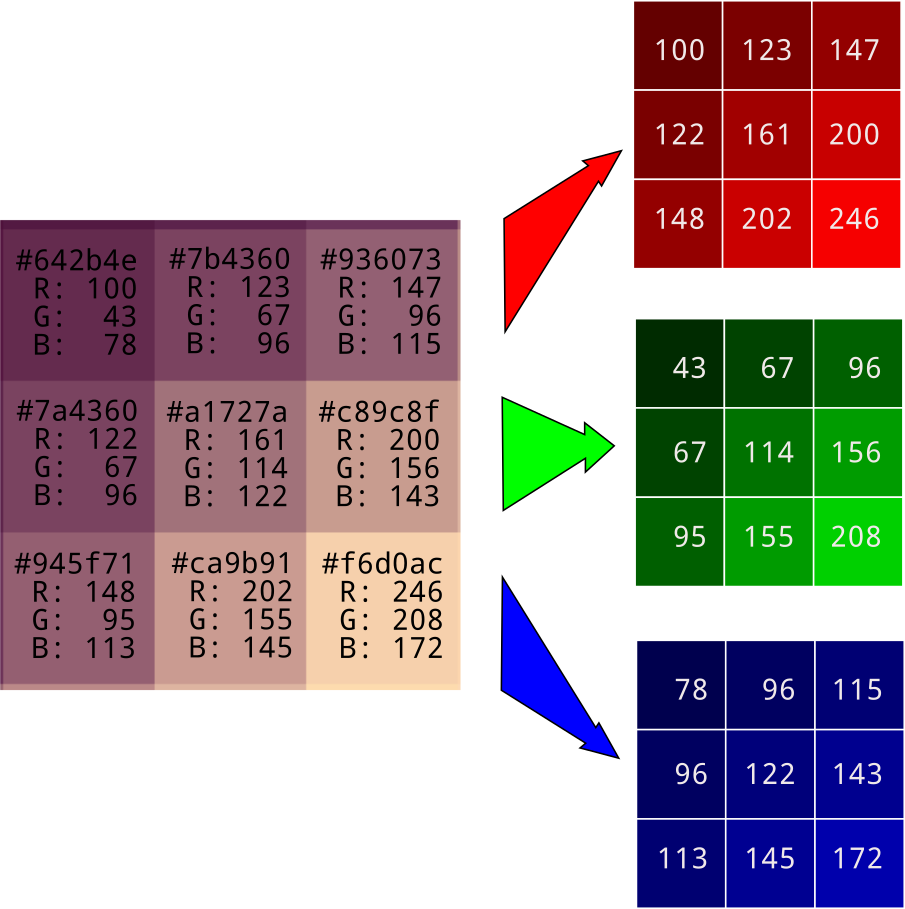
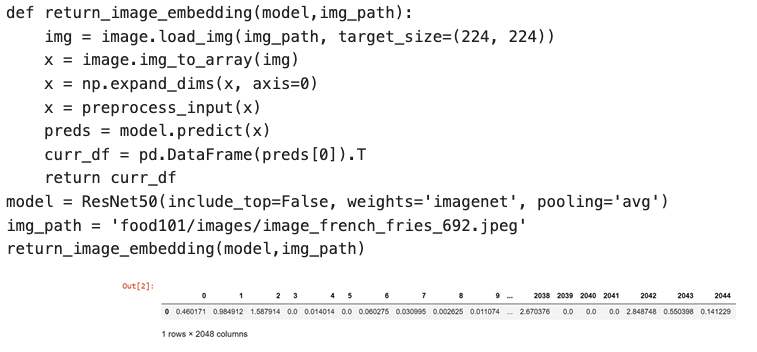
Embedding 是一种特殊的特征抽取方法,它将高维的输入数据(如图像或文本)映射到一个低维的连续向量空间,这个连续向量空间中的点可以表示原始输入数据的某种语义信息。在图像分类中,我们可以使用预训练的神经网络模型(如ResNet、Inception等)作为嵌入模型,将原始的图像数据转换成低维的特征向量,然后再基于这些特征向量来训练我们的分类模型。在我们的例子中,我们将图片从像素空间映射到了一个更小的、更易处理的空间。通过这种方式,我们可以用更少的数据来表示一张图片,同时保留了图片中的关键信息。下面展示了一段使用tensorflow生成一张图片embedding的代码,其生成结果是一个1x2048的向量。
Embedding的相似度
通过Embedding我们将2个图像的相关性问题转化为了判断2个vector相似度问题。通过计算2个vector的余弦距离(1 - Cosine Similarity)就是其中常用的一种方法。
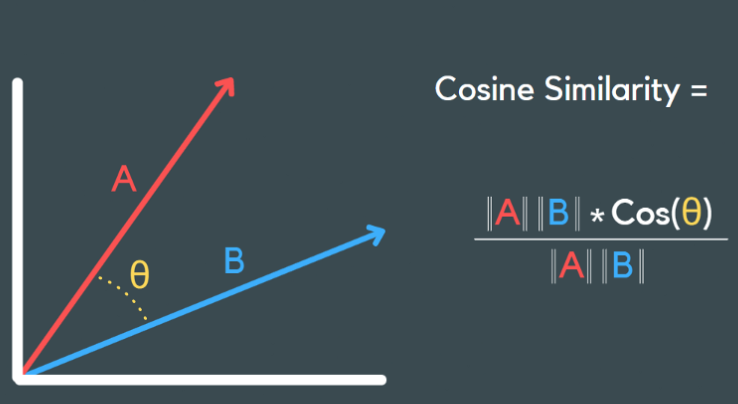
其他计算方式还有欧式距离、曼哈顿距离、马氏距离、KL散度、布朗距离协方差等。
图像分类算法
这里简单列出一些常见的图像分类算法,感兴趣的同学可以深入研究(太复杂就不多说了🤦♂️),Apple在这里也没明确给出自己用的是哪个模型,大概率是CNN或者ResNet。
- 支持向量机(Support Vector Machines,SVM):SVM是一种经典的监督学习算法,在图像分类中也有广泛应用。它通过在特征空间中构建一个最优超平面来实现分类。
- 决策树(Decision Trees):决策树是一种基于树结构的分类算法,可以根据图像的特征进行分割和分类。
- 随机森林(Random Forest):随机森林是一种集成学习方法,由多个决策树组成。它通过投票或平均多个决策树的预测结果来进行分类。
- K最近邻算法(K-Nearest Neighbors,KNN):KNN是一种简单而直观的分类算法。它根据离待分类样本最近的K个邻居的类别来确定该样本的类别。
- 多层感知机(Multilayer Perceptron,MLP):MLP是一种前馈神经网络,常用于图像分类。它由多个全连接层组成,可以学习和提取图像的特征。
- 卷积神经网络(Convolutional Neural Networks,CNN):CNN是最常用的图像分类算法之一。它通过使用卷积层、池化层和全连接层来自动学习图像中的特征并进行分类。
- 深度学习模型(如ResNet、Inception、VGG等):这些是基于深度神经网络的先进模型,具有更强大的学习能力和更好的性能。这些模型通常在大规模数据集上进行预训练,并在图像分类任务中进行微调。
开始训练
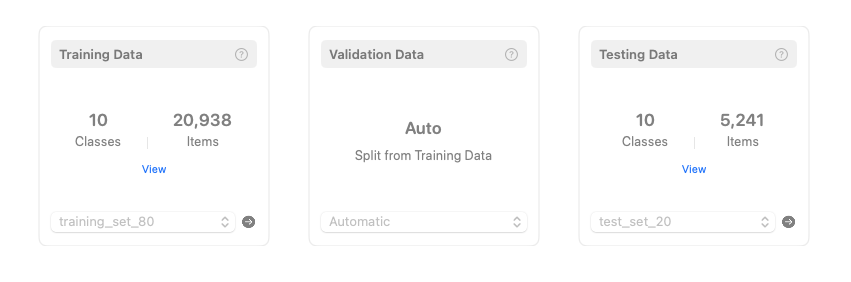
回到Create ML,我们将预处理好的训练集和测试集分别拖到对应的位置,Create ML便会自动识别数据集的内容,同时自动划分出一部分数据作为验证集。
Create ML为我们提供了一些可选的训练参数,2种feature extractor(特征抽取器)可选,V2相比V1抽取的更快需要的空间更好,但是系统兼容性不如V1。迭代次数默认为25次,augmetations(增强)选项里我们可以对训练数据添加不同变体来强化训练的效果,比如加入噪声、翻转和裁切等。
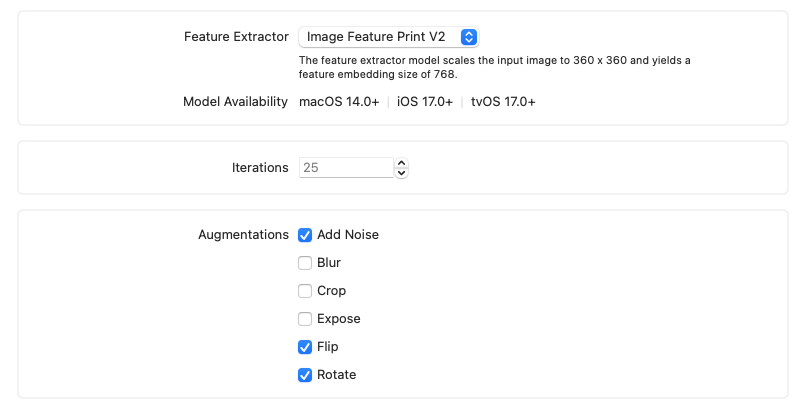
至此,我们就可以开始训练模型了,特征抽取是核心过程,整个过程持续了5~10分钟,随后就是完成25次迭代计算,在这个过程中,我们的模型逐渐收敛,create ML提供了实时的可视化训练曲线。训练结束后当即给出在训练集和验证集上的准确率,同时自动运行测试集,并给出最终的测试准确率。


在Evaluation页面中,我们可以直观地看到训练结果的各项详细指标,同时它会给出识别错误最多的一些图片,方便我们针对性地对这些图片再次训练。
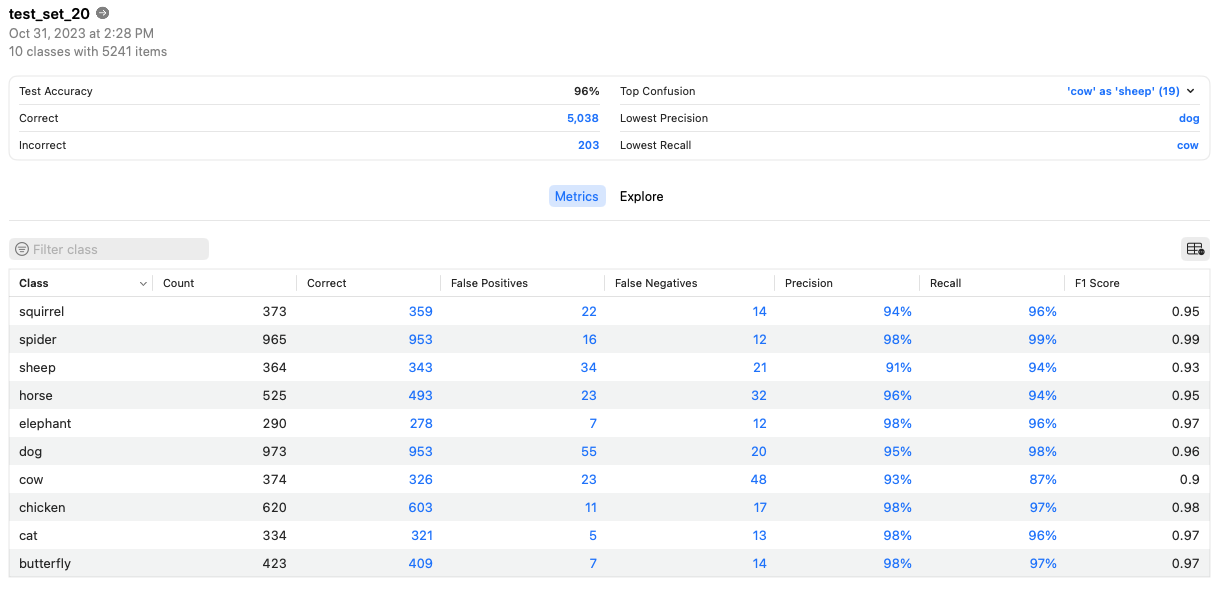

评价指标
在训练结果中有4项重要的评估指标:accuracy、precision、recall和F1 Score,下面简单介绍下这些指标的含义以及对应的计算方式。
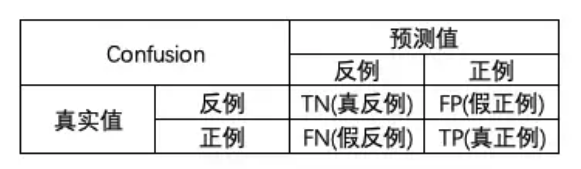
混淆矩阵(Confusion Matrix)
一般通过机器学习会产生四类结果:TN、TP、FN和FP。真正例和真反例是被正确预测的数据,假正例和假反例是被错误预测的数据。
- TP(True Positive):被正确预测的正例。即该数据的真实值为正例,预测值也为正例的情况;
- TN(True Negative):被正确预测的反例。即该数据的真实值为反例,预测值也为反例的情况;
- FP(False Positive):被错误预测的正例。即该数据的真实值为反例,但被错误预测成了正例的情况;
- FN(False Negative):被错误预测的反例。即该数据的真实值为正例,但被错误预测成了反例的情况。
准确率(Accuracy)
分类正确的样本占总样本个数的比例
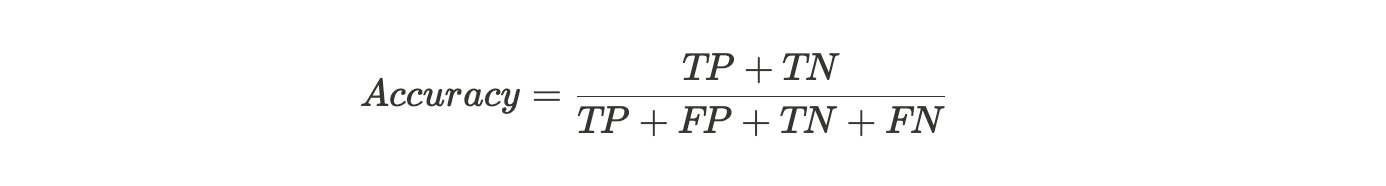
Accuracy是衡量分类模型的最直白的指标,但缺陷也是明显的。假设有100个样本,其中有99个都是正样本,则分类器只需要一直预测为正例,就可以得到99%的准确率,实际上这个分类器性能是很低下的。也就是说,当不同类别的样本所占的比例严重不平衡时,占比大的类别会是影响准确率的最主要的因素。所以,只有当数据集各个类别的样本比例比较均衡时,Accuracy这个指标才是一个比较好的衡量标准。因此,必须参考其他指标才能完整评估模型的性能。
精确率(Precision)
预测结果中真正例占所有预测为正例的比例(测重找的对)
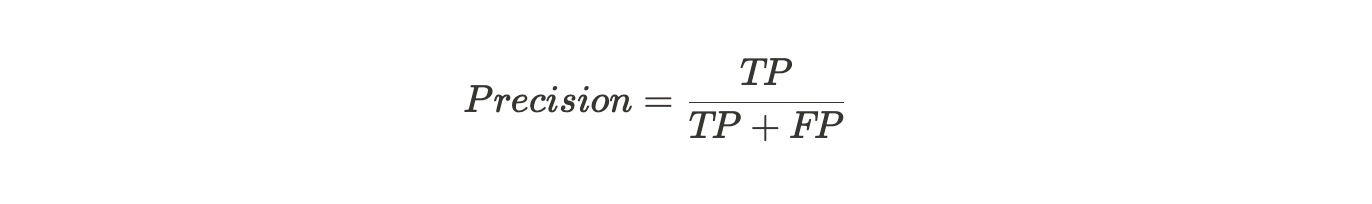
使用场景:当反例被错误预测成正例(FP)的代价很高时,适合用精确率。根据公式可知,精确率越高,FP越小。比如在垃圾在垃圾邮件检测中,假正例意味着非垃圾邮件(实际为负)被错误的预测为垃圾邮件(预测为正)。如果一个垃圾邮件监测系统的查准率不高导致很多非垃圾邮件被归到垃圾邮箱里去,那么邮箱用户可能会丢失或者漏看一些很重要的邮件。
召回率(Recall)
样本中的正例有多少被正确预测(测重找的全)
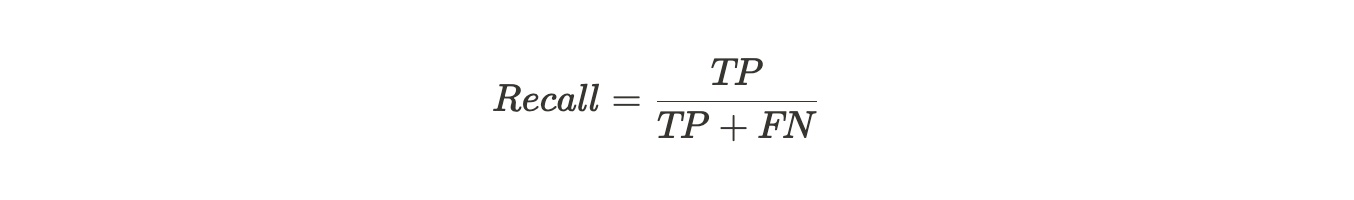
使用场景:当正例被错误的预测为反例(FN)产生的代价很高时,适合用召回率。根据公式可知,召回率越高,FN越小。比如说在银行的欺诈检测或医院的病患者检测中,如果将欺诈性交易(实际为正)预测为非欺诈性交易(预测为负),则可能会给银行带来非常严重的损失。再比如以最近的新冠疫情为例,如果一个患病者(实际为正)经过试剂检测被预测为没有患病(预测为负),这样的假反例或者说假阴性产生的风险就非常大。
F1 Score
F1 score是精确率和召回率的一个加权平均
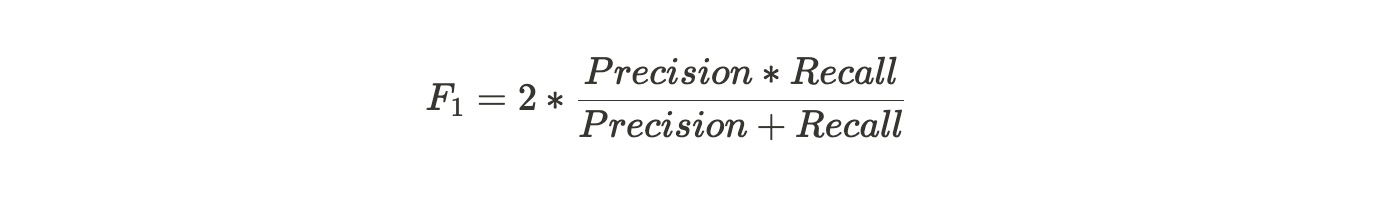
Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;Recall体现了模型对正样本的识别能力,Recall越高,模型对正样本的识别能力越强。F1 score是两者的综合,F1 score越高,说明模型越稳健。
因此,我们的目标就是通过不断调整训练集以及各种参数来使得最终训练完成后的模型可以在各项指标中获得更高得分。
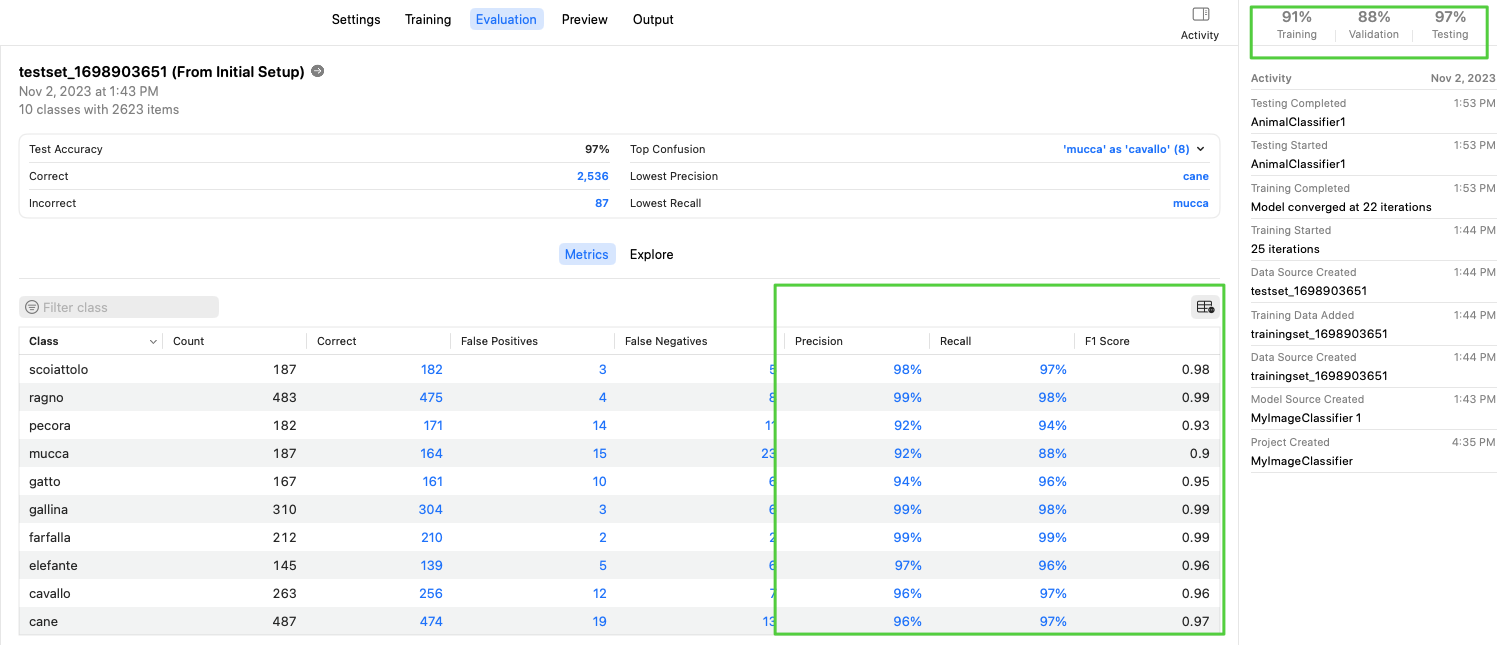
在调整了训练集和参数后,第二次训练的效果相较第一次有了显著提升。
将模型应用到App
在Output选项中,我们可以直接下载模型或者直接在Xcode中打开,模型的格式是.mlmodel,可以看到我们这个小模型只有56kb。
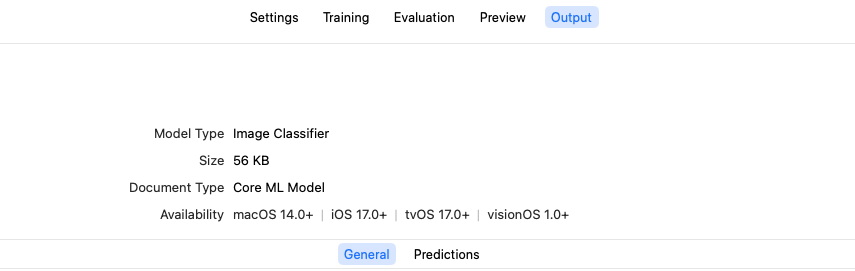
直接将模型拖入你的Xcode项目就可以自动导入了,接下来就是在代码层通过调用Vision框架的API接口实现对一张图片的识别。
创建VNCoreMLModel
Xcode直接将我们的模型映射成了对应的Swift类:MyImageClassifier,通过逐层解包我们最终拿到一个VNCoreMLModel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static func createImageClassifier() -> VNCoreMLModel {
// Use a default model configuration.
let defaultConfig = MLModelConfiguration()
// Create an instance of the image classifier's wrapper class.
let imageClassifierWrapper = try? MyImageClassifier(configuration: defaultConfig)
guard let imageClassifier = imageClassifierWrapper else {
fatalError("App failed to create an image classifier model instance.")
}
// Get the underlying model instance.
let imageClassifierModel = imageClassifier.model
// Create a Vision instance using the image classifier's model instance.
guard let imageClassifierVisionModel = try? VNCoreMLModel(for: imageClassifierModel) else {
fatalError("App failed to create a `VNCoreMLModel` instance.")
}
return imageClassifierVisionModel
}
创建VNCoreMLRequest
每一次调用Core ML对图片进行识别都是一次VNCoreMLRequest,类似网络请求。
1
2
3
4
5
6
7
8
9
private func createImageClassificationRequest() -> VNImageBasedRequest {
// Create an image classification request with an image classifier model.
let imageClassificationRequest = VNCoreMLRequest(model: ImagePredictor.imageClassifier,
completionHandler: visionRequestHandler)
imageClassificationRequest.imageCropAndScaleOption = .centerCrop
return imageClassificationRequest
}
执行图像分类请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
func makePredictions(for photo: UIImage, completionHandler: @escaping ImagePredictionHandler) throws {
let orientation = CGImagePropertyOrientation(photo.imageOrientation)
guard let photoImage = photo.cgImage else {
fatalError("Photo doesn't have underlying CGImage.")
}
let imageClassificationRequest = createImageClassificationRequest()
predictionHandlers[imageClassificationRequest] = completionHandler
let handler = VNImageRequestHandler(cgImage: photoImage, orientation: orientation)
let requests: [VNRequest] = [imageClassificationRequest]
// Start the image classification request.
try handler.perform(requests)
解析完成后的回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
private func visionRequestHandler(_ request: VNRequest, error: Error?) {
// Remove the caller's handler from the dictionary and keep a reference to it.
guard let predictionHandler = predictionHandlers.removeValue(forKey: request) else {
fatalError("Every request must have a prediction handler.")
}
// Start with a `nil` value in case there's a problem.
var predictions: [Prediction]? = nil
// Call the client's completion handler after the method returns.
defer {
// Send the predictions back to the client.
predictionHandler(predictions)
}
// Check for an error first.
if let error = error {
print("Vision image classification error...\n\n\(error.localizedDescription)")
return
}
// Check that the results aren't `nil`.
if request.results == nil {
print("Vision request had no results.")
return
}
// Cast the request's results as an `VNClassificationObservation` array.
guard let observations = request.results as? [VNClassificationObservation] else {
// Image classifiers, like MobileNet, only produce classification observations.
// However, other Core ML model types can produce other observations.
// For example, a style transfer model produces `VNPixelBufferObservation` instances.
print("VNRequest produced the wrong result type: \(type(of: request.results)).")
return
}
// Create a prediction array from the observations.
predictions = observations.map { observation in
// Convert each observation into an `ImagePredictor.Prediction` instance.
Prediction(classification: observation.identifier,
confidencePercentage: observation.confidencePercentageString)
}
}
运行效果
分别用🐈、🦋以及一个🐈手办进行测试,都可以给出相对准确度的识别结果。

写在结尾
除了Create ML提供的自带模型,Apple官方还提供了一系列热门的预训练模型,全都是Core ML格式的,在https://developer.apple.com/machine-learning/models/这个地址可以直接下载使用。Create ML和Core ML的出现极大降低了开发者入门机器学习的门槛,相信通过结合自身的业务场景和数据后,端AI将会有更多新的玩法和机会。
References
Classifying Images with Vision and Core ML
一文看懂 AI 数据集:训练集、验证集、测试集(附:分割方法+交叉验证)
Recommending Similar Images using Image Embedding